Intelligent Data Extractor and Analyzer(IDEA)

Main Idea
Why IDEA?▪ Lot of manual effort is spent in reading through all the documents, extracting the relevant information, categorizing it into actionable information ▪ The manual process results in cost overruns, quality issues and delays. ▪ There is a real need for an automated solution to extract relevant information, identify the respective departments and highlight the summary of the documents
Highlights
▪ Read and extract data from unstructured sources through an automated process ▪ Aid in text classification, clustering and analytics using NLP, Machine learning algorithms and models ▪ Automated build of Summary and Details ▪ Extract Report Layouts ▪ Categorize the text using Machine learning models and techniques ▪ Transform into meaningful insights
High-level visualization
High-level visualization of the project.
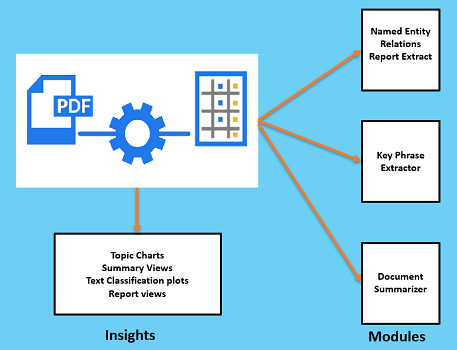
IDEA steps
1. Source▪ Data sources can be structured or unstructured. PDF is taken as the source here.
2. Analyze Analyzer engine comprises of:-▪ Reader - Read the source documents by downloading from web pages(URL) or direct uploads. ▪ Extractor - Scan the whole document or the selective pages, apply filters if any performs Regex operations. ▪ Parser - Split the text into:
Sentences, Tokens, Part of Speech Tagging Named entity, Relationships N-grams, Key Phrases
3. Learn▪ Classify text using machine learning algorithms. ▪ Extract Topics ▪ Extract document Summary
4. Insights▪ Summary views, text categories, topic charts and sentiments in CSV/XL ▪ Key phrases, Field values and Information can be viewed in the CSV format ▪ Report layouts can be downloaded as CSV/HTML format